netfilterについて
netfilterは、Linuxカーネルのデータプレーン中のいくつかの地点に任意の関数をattachすることができるようにしてくれるフレームワークである。netfilterはLinuxのネットワーク機能を実装する際の基礎になるフレームワークで、iptablesやconntrackで利用されている。ここでは、netfilterがどのようなものなのか、どのように実装されているのかという点についてまとめた。
概要
先述の通りnetfilterは、Linuxカーネルのデータプレーン中のいくつかの地点に任意の関数をattachすることができるようにしてくれるフレームワークである。以下に、netfilterの概要図を示す。netfilterは、PREROUTING, INPUT, FORWARD, OUTPUT, POSTROUTINGの5つのフックポイントを提供してくれる。netfilterの利用者はこのフックポイントの好きな地点に任意の関数をattachすることができ、パケットがそのフローを通ったらその関数が実行される。
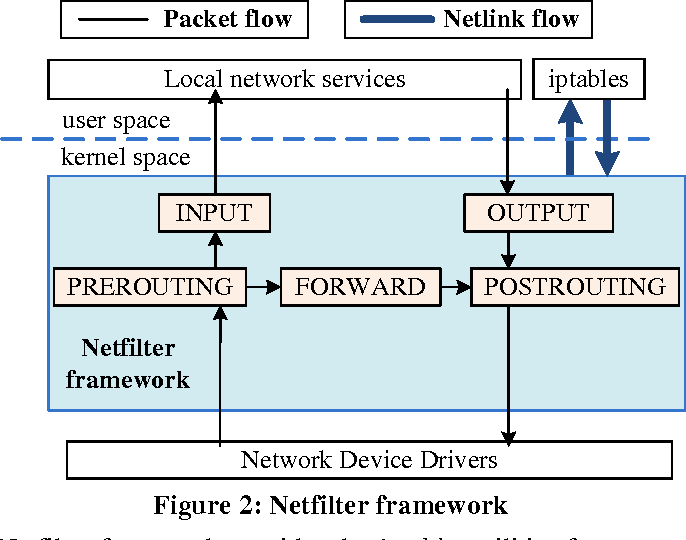
netfilterは、多くのLinuxの機能を実装するのに利用されている。代表的なのはiptablesなどのファイアウォール機能だろう。iptablesでは、それぞれのフックポイントで対応するチェインに含まれているルールを逐次評価し、パケットのフィルタリングやロードバランシング、NATなどの機能を提供している。また、conntrackでは、データプレーンを流れるコネクションを追跡するためにnetfilterを利用している。パケットがカーネルに入ってくるPREROUTING, OUTPUTでそのパケットがどのコネクションの通信なのかを判別し、後段に存在するiptablesなどがそのコネクションの情報を利用してステートフルにパケットをフィルタリングしたり、NATのセッションを発見して適切にアドレス変換を行うなどをしている。
また、ネットワークの機能だけではなく、AppArmorやSELinuxなどのMandatory Access Control機能でもnetfilterは利用される。あるプロセスから出る通信が認可されている地点への通信なのかどうかを判別し、もし認可されていなければその通信を遮断するといった目的でnetfilterが利用されている。
このように、netfilterはLinuxの多くの機能を実現するための基盤として利用されている。
フックポイントの定義
では、これらのフックポイントはLinux内でどのように定義されているのだろうか?netfilterのフックポイントの多くは、NF_HOOKを利用して定義されている。一部については、NF_HOOKの内部で呼んでいるnf_hookを直接呼び出している。このどちらかを利用している地点がフックポイントになる。NF_HOOKを参照している地点を検索すると、それなりに多くの地点から参照されていることが分かる。
NF_HOOK identifier - Linux source code (v5.15) - Bootlin
nf_hook identifier - Linux source code (v5.15) - Bootlin
実際にフックポイントが定義されている場所を見てみよう。以下に、ip_local_deliverを示す。この関数は、IPルーティングが行われた後に、ホスト宛のパケットが通る関数である。この関数の最後で、NF_HOOKが呼び出されている。このようにしてフックポイントを定義している。ip_local_deliverでは、INPUTチェインのフックポイントが定義されている。
int ip_local_deliver(struct sk_buff *skb) { /* * Reassemble IP fragments. */ struct net *net = dev_net(skb->dev); if (ip_is_fragment(ip_hdr(skb))) { if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER)) return 0; } return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, net, NULL, skb, skb->dev, NULL, ip_local_deliver_finish); }
NF_HOOKの定義を見てみよう。NF_HOOKはnf_hookの非常に薄いラッパー関数なので、retに応じてokfnを呼び出すか否かという点が異なる。
static inline int NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb, struct net_device *in, struct net_device *out, int (*okfn)(struct net *, struct sock *, struct sk_buff *)) { int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn); if (ret == 1) ret = okfn(net, sk, skb); return ret; }
netfilter.h - include/linux/netfilter.h - Linux source code (v5.15) - Bootlin
第一引数のpfはプロトコルファミリーを表している。netfilterでは、IPレベルのデータパスだけではなく、ブリッジレベルのデータパスだったり、ARPのデータパスにも同じように関数をアタッチする仕組みが存在する。この中では、NFPROTO_IPV4, NFPROTO_IPV6に限定してまとめているが、他のプロトコルファミリーでも同様な処理が行われている。以下にプロトコルファミリーの一覧を示す。
enum { NFPROTO_UNSPEC = 0, NFPROTO_INET = 1, NFPROTO_IPV4 = 2, NFPROTO_ARP = 3, NFPROTO_NETDEV = 5, NFPROTO_BRIDGE = 7, NFPROTO_IPV6 = 10, NFPROTO_DECNET = 12, NFPROTO_NUMPROTO, };
netfilter.h - include/uapi/linux/netfilter.h - Linux source code (v5.15) - Bootlin
第二引数のhookはフックポイントを表している。この部分はプロトコルファミリー毎に定義されている。ここでは、IPv4, IPv6で利用されるフックポイントについて見ていく。IPv4, IPv6では、以下のようなフックポイントが存在する。これは、それぞれ先に述べたPREROUTING, INPUT, FORWARD, OUTPUT, POSTROUTINGに対応している。他にも、NFPROTO_ARPでは、NF_ARP_IN, NF_ARP_OUT, NF_ARP_FORWARDなどのフックポイントが定義されている。
enum nf_inet_hooks {
NF_INET_PRE_ROUTING,
NF_INET_LOCAL_IN,
NF_INET_FORWARD,
NF_INET_LOCAL_OUT,
NF_INET_POST_ROUTING,
NF_INET_NUMHOOKS,
NF_INET_INGRESS = NF_INET_NUMHOOKS,
};
最後の引数は、nf_hookの結果としてACCEPTが返された時に呼び出される関数である。それ以外の引数については以下の通りである。net, skbは常に存在しているが、sk, in, outはフックポイントによってはNULLが代入される。例えば、NF_INET_LOCAL_INの呼び出しにおけるsk, outやNF_INET_LOCAL_OUTの呼び出しにおけるinは定義不能である。
- struct net *net: 現在のnetwork namespaceを表す構造体(常に存在する)
- struct sock *sk: ソケットを表す構造体
- struct sk_buff *skb: パケット本体を表す構造体
- struct net_device *in: 入力デバイスを表す構造体
- struct net_device *out: 出力デバイスを表す構造体
nf_hook
それでは次に、NF_HOOKの内部で呼び出されていたnf_hookについて見ていく。とはいっても、非常に構造はシンプルである。まずはじめに、第一引数, 第二引数に与えられたプロトコルファミリーとフックポイントの情報から、フック関数のリストを取得し、hook_headに代入する。
static inline int nf_hook(u_int8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb, struct net_device *indev, struct net_device *outdev, int (*okfn)(struct net *, struct sock *, struct sk_buff *)) { struct nf_hook_entries *hook_head = NULL; int ret = 1; // snipped rcu_read_lock(); switch (pf) { case NFPROTO_IPV4: hook_head = rcu_dereference(net->nf.hooks_ipv4[hook]); break; case NFPROTO_IPV6: hook_head = rcu_dereference(net->nf.hooks_ipv6[hook]); break; // snipped }
nf_hook_entriesは、フック関数の個数を保持するnum_hook_entriesと、フック関数自体を保持するhooksから成る構造である。nf_hook_entryは、フック関数へのポインタとプライベートなデータ保存領域の対から成る。
struct nf_hook_entries { u16 num_hook_entries; struct nf_hook_entry hooks[]; };
netfilter.h - include/linux/netfilter.h - Linux source code (v5.15) - Bootlin
struct nf_hook_entry { nf_hookfn *hook; void *priv; };
netfilter.h - include/linux/netfilter.h - Linux source code (v5.15) - Bootlin
フック関数のリストが取得できた場合、nf_hook_slowを呼び出してフック関数を逐次呼び出していく。
if (hook_head) { struct nf_hook_state state; nf_hook_state_init(&state, hook, pf, indev, outdev, sk, net, okfn); ret = nf_hook_slow(skb, &state, hook_head, 0); } rcu_read_unlock(); return ret; }
nf_hook_slowでは、第三引数で与えられたnf_hook_entriesに格納されているフック関数を順番に呼び出し、フック関数から返されたverdictに対応する処理を行う。実際のフック関数の呼び出しはnf_hook_entry_hookfnで行っている。
int nf_hook_slow(struct sk_buff *skb, struct nf_hook_state *state, const struct nf_hook_entries *e, unsigned int s) { unsigned int verdict; int ret; for (; s < e->num_hook_entries; s++) { verdict = nf_hook_entry_hookfn(&e->hooks[s], skb, state);
後半部分では、フック関数から返されたverdictに応じて必要があればパケット処理を行っている。
switch (verdict & NF_VERDICT_MASK) { case NF_ACCEPT: break; case NF_DROP: kfree_skb(skb); ret = NF_DROP_GETERR(verdict); if (ret == 0) ret = -EPERM; return ret; case NF_QUEUE: ret = nf_queue(skb, state, s, verdict); if (ret == 1) continue; return ret; default: /* Implicit handling for NF_STOLEN, as well as any other * non conventional verdicts. */ return 0; } } return 1; }
このようにしてフックポイントから事前に登録された関数を呼び出している。
フック関数の登録
これまでのところで、フックポイントがどのように定義されて、どのようにしてフック関数が呼び出されるのかについて見てきた。今度は逆にフック関数を登録する側について見ていく。フック関数を登録するには、nf_register_net_hooksを利用して登録を行う。第一引数はnetwork namespaceを、第二引数は登録する関数を、第三引数では何個登録するのかを指定する。
int nf_register_net_hooks(struct net *net, const struct nf_hook_ops *reg, unsigned int n);
core.c - net/netfilter/core.c - Linux source code (v5.15) - Bootlin
では次に、実際にiptablesで利用されるフック関数の登録について見ていく。ここでは、AppArmorで利用されるフック関数の登録例について見ていく。iptables等でもwrapper関数を経由しているが、同様に登録が行われているので興味がある場合は適宜参照してもらいたい。AppArmorでは、apparmor_nf_registerでnetfilterのフック関数の登録を行っている。第二引数のapparmor_nf_opsで、実際のフック関数の定義が行われている。
static int __net_init apparmor_nf_register(struct net *net) { int ret; ret = nf_register_net_hooks(net, apparmor_nf_ops, ARRAY_SIZE(apparmor_nf_ops)); return ret; }
フック関数の定義には、関数ポインタが代入されるhook, NF_HOOKで指定されていたpf, hooknum(hookと同義)以外にもpriorityという項目がある。これは名前の通りで、登録するフック関数の優先度を示しており、プロトコルファミリー毎に定義されている。細かい順番は実装するのでなければ覚えておく必要はないと思うが、この優先度を見ると、iptablesのテーブル毎の優先度(raw → mangle → filter → securityの順序で実行される)だったり、Destination NATがSource NATよりも先に実行されることなどが分かる。
static const struct nf_hook_ops apparmor_nf_ops[] = { { .hook = apparmor_ipv4_postroute, .pf = NFPROTO_IPV4, .hooknum = NF_INET_POST_ROUTING, .priority = NF_IP_PRI_SELINUX_FIRST, }, #if IS_ENABLED(CONFIG_IPV6) { .hook = apparmor_ipv6_postroute, .pf = NFPROTO_IPV6, .hooknum = NF_INET_POST_ROUTING, .priority = NF_IP6_PRI_SELINUX_FIRST, }, #endif };
enum nf_ip_hook_priorities { NF_IP_PRI_FIRST = INT_MIN, NF_IP_PRI_RAW_BEFORE_DEFRAG = -450, NF_IP_PRI_CONNTRACK_DEFRAG = -400, NF_IP_PRI_RAW = -300, NF_IP_PRI_SELINUX_FIRST = -225, NF_IP_PRI_CONNTRACK = -200, NF_IP_PRI_MANGLE = -150, NF_IP_PRI_NAT_DST = -100, NF_IP_PRI_FILTER = 0, NF_IP_PRI_SECURITY = 50, NF_IP_PRI_NAT_SRC = 100, NF_IP_PRI_SELINUX_LAST = 225, NF_IP_PRI_CONNTRACK_HELPER = 300, NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX, NF_IP_PRI_LAST = INT_MAX, };
次に登録される関数側について見ていく。第一引数のprivには処理に必要なステートを指すポインタが渡される。第二引数はパケット自体、第三引数はnf_hook_slowを呼ぶ際に用意していたステートが渡される。第三引数のステートを経由して、NF_HOOKを呼ぶ時に渡された、ソケットの情報や入出力デバイスの情報を参照することができる。フック関数では、その後のパケットの処遇を返す必要があり、ここではNF_ACCEPTなどの値が返されている。
static unsigned int apparmor_ip_postroute(void *priv, struct sk_buff *skb, const struct nf_hook_state *state) { struct aa_sk_ctx *ctx; struct sock *sk; if (!skb->secmark) return NF_ACCEPT; sk = skb_to_full_sk(skb); if (sk == NULL) return NF_ACCEPT; ctx = SK_CTX(sk); if (!apparmor_secmark_check(ctx->label, OP_SENDMSG, AA_MAY_SEND, skb->secmark, sk)) return NF_ACCEPT; return NF_DROP_ERR(-ECONNREFUSED); } static unsigned int apparmor_ipv4_postroute(void *priv, struct sk_buff *skb, const struct nf_hook_state *state) { return apparmor_ip_postroute(priv, skb, state); }
この関数の中でパケットの処理を行うことで、iptablesやconntrackなどの処理が実現されている。
まとめ
iptablesやconntrackなどの基盤になるnetfilterについて、概要やその実装についてまとめた。もっと細かい部分についてはおいおい追記していくかもしれない。